关于这俩c库函数的使用方法,百度上一搜能搜到很多,但是实际上用了这么多年的我有时候还是会犯迷糊,分不清哪个是处理0结尾的,哪个是没有的,因此今天趁着放假有时间,再整理记录一下。
#include <cstring>
int main(int argc, char *argv[])
{
char sz_test1[10] = {};
char sz_test2[10] = {};
char sz_source[10] = "123456789";
strncpy(sz_test1, sz_source, 10);
snprintf(sz_test2, 10, "%s", sz_source);
return 0;
}
上面是一段很简单的写在cpp里的c代码,纯c也差不多,主要说的是这俩c函数的区别,可以看到sz_source有9个字符,带1个结尾0凑成10字节的字符串,上面还有两个同样是10字节的char缓冲区用于测试,可以看到strncpy和snprintf的n都给10的时候,sz_test1和sz_test2都是和sz_source一样的结果,包括结尾0。
接下来把两个函数的n都换成9,这时候可以看到如下结果:
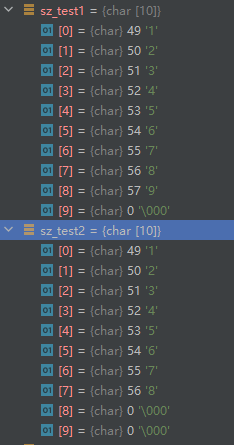
test1还是和source一样,而test2变成了12345678的0结尾字符串,少了一个9,也就是说snprintf的n是包含了结尾0的处理的,也就是写的9,实际上是拷了8个字符+1个0结尾,而strncpy的n,则是指的不包含0结尾的字符数,所以写的9也好,写10也好,最后都完整拷贝了source的9个字符。继续减n到8可以看到用strncpy的test1变成了到8结束,用snprintf的test2则变成了到7结束。
接下来,修改下刚才的代码,换成一个特殊些的情况:
#include <cstring>
int main(int argc, char *argv[])
{
char sz_test1[10] = {};
char sz_test2[10] = {};
char sz_source[10] = {'1', '2', '3', '4', '5', '6', '7', '8', '9', 'A'};
strncpy(sz_test1, sz_source, 10);
snprintf(sz_test2, 10, "%s", sz_source);
return 0;
}
这次,source的初始化不再以0结尾字符串方式处理,而换成了直接用满10个字节的缓冲区形式,也就是说source不再是标准的0结尾字符串了,这个时候可以看到n还给10的话,结果如下:
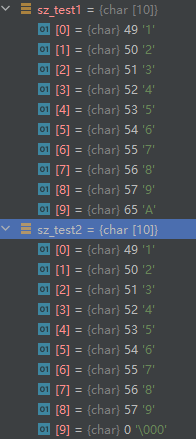
可以看到,test1和source一样,占满了10个字节,没有0结尾,而,test2则还是个0结尾的c字符串,字符拷贝到了9!
所以从这点来看,一般我们处理这种字符拷贝的时候,会把n写成目标缓冲的大小,比如sizeof(sz_test1),也就是编译器就能确定的10,而这时,如果源缓冲不是0结尾字符串的话,就会导致strncpy得到的结果也不是0结尾,后续访问的时候处理不好就会出内存访问问题,相对来说snprintf的n也给sizeof目标缓冲大小的话,就更安全些,怎么都会加上结尾0,内容部分则会出现截断。
博主友情提示:
如您在评论中需要提及如QQ号、电子邮件地址或其他隐私敏感信息,欢迎使用>>博主专用加密工具v3<<处理后发布,原文只有博主可以看到。
